A Basic Model¶
In this example application it is shown how a simple time series model can be developed to simulate groundwater levels. The recharge (calculated as precipitation minus evaporation) is used as the explanatory time series.
[1]:
import matplotlib.pyplot as plt
import pandas as pd
import pastas as ps
ps.show_versions()
Python version: 3.7.8 | packaged by conda-forge | (default, Jul 31 2020, 02:37:09)
[Clang 10.0.1 ]
Numpy version: 1.18.5
Scipy version: 1.4.0
Pandas version: 1.1.2
Pastas version: 0.16.0b
Matplotlib version: 3.1.3
1. Importing the dependent time series data¶
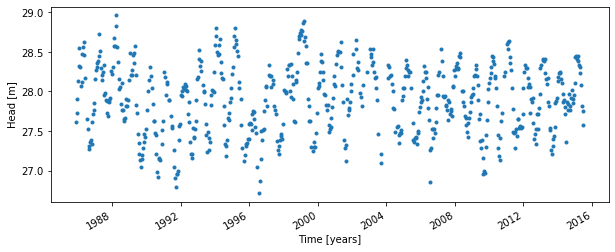
In this codeblock a time series of groundwater levels is imported using the read_csv function of pandas. As pastas expects a pandas Series object, the data is squeezed. To check if you have the correct data type (a pandas Series object), you can use type(oseries) as shown below.
The following characteristics are important when importing and preparing the observed time series: - The observed time series are stored as a pandas Series object. - The time step can be irregular.
[2]:
# Import groundwater time seriesm and squeeze to Series object
gwdata = pd.read_csv('../data/head_nb1.csv', parse_dates=['date'],
index_col='date', squeeze=True)
print('The data type of the oseries is: %s' % type(gwdata))
# Plot the observed groundwater levels
gwdata.plot(style='.', figsize=(10, 4))
plt.ylabel('Head [m]');
plt.xlabel('Time [years]');
The data type of the oseries is: <class 'pandas.core.series.Series'>
2. Import the independent time series¶
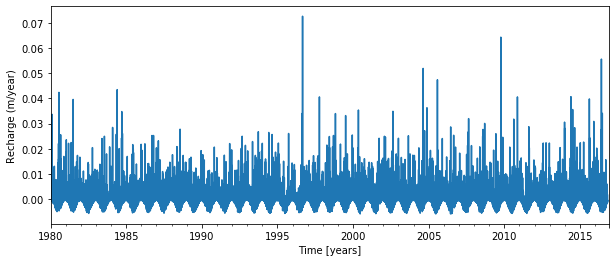
Two explanatory series are used: the precipitation and the potential evaporation. These need to be pandas Series objects, as for the observed heads.
Important characteristics of these time series are: - All series are stored as pandas Series objects. - The series may have irregular time intervals, but then it will be converted to regular time intervals when creating the time series model later on. - It is preferred to use the same length units as for the observed heads.
[3]:
# Import observed precipitation series
precip = pd.read_csv('../data/rain_nb1.csv', parse_dates=['date'],
index_col='date', squeeze=True)
print('The data type of the precip series is: %s' % type(precip))
# Import observed evaporation series
evap = pd.read_csv('../data/evap_nb1.csv', parse_dates=['date'],
index_col='date', squeeze=True)
print('The data type of the evap series is: %s' % type(evap))
# Calculate the recharge to the groundwater
recharge = precip - evap
print('The data type of the recharge series is: %s' % type(recharge))
# Plot the time series of the precipitation and evaporation
plt.figure()
recharge.plot(label='Recharge', figsize=(10, 4))
plt.xlabel('Time [years]')
plt.ylabel('Recharge (m/year)');
The data type of the precip series is: <class 'pandas.core.series.Series'>
The data type of the evap series is: <class 'pandas.core.series.Series'>
The data type of the recharge series is: <class 'pandas.core.series.Series'>
3. Create the time series model¶
In this code block the actual time series model is created. First, an instance of the Model class is created (named ml here). Second, the different components of the time series model are created and added to the model. The imported time series are automatically checked for missing values and other inconsistencies. The keyword argument fillnan can be used to determine how missing values are handled. If any nan-values are found this will be reported by pastas.
[4]:
# Create a model object by passing it the observed series
ml = ps.Model(gwdata, name="GWL")
# Add the recharge data as explanatory variable
sm = ps.StressModel(recharge, ps.Gamma, name='recharge', settings="evap")
ml.add_stressmodel(sm)
INFO: Cannot determine frequency of series head.
INFO: Nan-values were removed at the end of the series.
INFO: Inferred frequency for time series None: freq= D
4. Solve the model¶
The next step is to compute the optimal model parameters. The default solver uses a non-linear least squares method for the optimization. The python package scipy is used (info on scipy's least_squares solver can be found here). Some standard optimization statistics are reported along with the optimized parameter values and correlations.
[5]:
ml.solve()
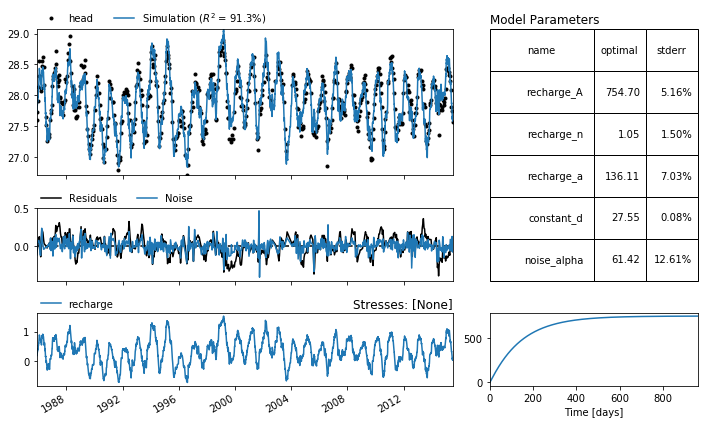
Fit report GWL Fit Statistics
==================================================
nfev 11 EVP 91.28
nobs 644 R2 0.91
noise True RMSE 0.13
tmin 1985-11-14 00:00:00 AIC 5.32
tmax 2015-06-28 00:00:00 BIC 27.66
freq D Obj 2.09
warmup 3650 days 00:00:00 ___
solver LeastSquares Interpolated No
Parameters (5 were optimized)
==================================================
optimal stderr initial vary
recharge_A 754.698599 ±5.16% 215.674528 True
recharge_n 1.054302 ±1.50% 1.000000 True
recharge_a 136.110198 ±7.03% 10.000000 True
constant_d 27.551737 ±0.08% 27.900078 True
noise_alpha 61.418939 ±12.61% 15.000000 True
Parameter correlations |rho| > 0.5
==================================================
recharge_A recharge_a 0.86
constant_d -0.79
recharge_n recharge_a -0.71
recharge_a constant_d -0.68
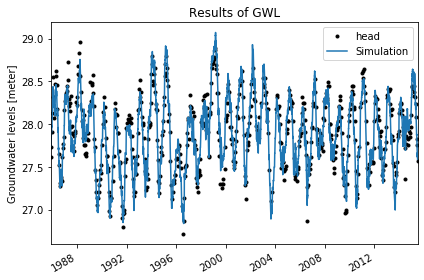
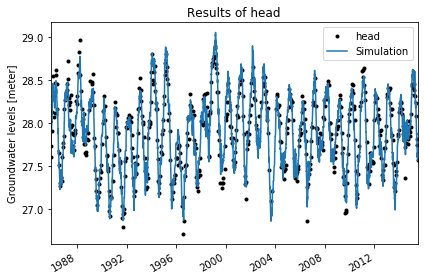
5. Plot the results¶
The solution can be plotted after a solution has been obtained.
[6]:
ml.plot()
[6]:
<matplotlib.axes._subplots.AxesSubplot at 0x7f9cf4ab3b10>
6. Advanced plotting¶
There are many ways to further explore the time series model. pastas has some built-in functionalities that will provide the user with a quick overview of the model. The plots subpackage contains all the options. One of these is the method plots.results which provides a plot with more information.
[7]:
ml.plots.results(figsize=(10, 6))
[7]:
[<matplotlib.axes._subplots.AxesSubplot at 0x7f9cf4947a90>,
<matplotlib.axes._subplots.AxesSubplot at 0x7f9cf4a64350>,
<matplotlib.axes._subplots.AxesSubplot at 0x7f9cf4f1cad0>,
<matplotlib.axes._subplots.AxesSubplot at 0x7f9cf4f58cd0>,
<matplotlib.axes._subplots.AxesSubplot at 0x7f9cf503f1d0>]
7. Statistics¶
The stats subpackage includes a number of statistical functions that may applied to the model. One of them is the summary method, which gives a summary of the main statistics of the model.
[8]:
ml.stats.summary()
[8]:
| Value | |
|---|---|
| Statistic | |
| rmse | 0.126944 |
| rmsn | 0.080829 |
| sse | 10.375993 |
| mae | 0.101292 |
| nse | 0.912846 |
| evp | 91.284860 |
| rsq | 0.912789 |
| bic | 27.659504 |
| aic | 5.321010 |
8. Improvement: estimate evaporation factor¶
In the previous model, the recharge was estimated as precipitation minus potential evaporation. A better model is to estimate the actual evaporation as a factor (called the evaporation factor here) times the potential evaporation. First, new model is created (called ml2 here so that the original model ml does not get overwritten). Second, the StressModel2 object is created, which combines the precipitation and evaporation series and adds a parameter for the evaporation factor f.
The StressModel2 object is added to the model, the model is solved, and the results and statistics are plotted to the screen. Note that the new model gives a better fit (lower root mean squared error and higher explained variance), but that the Akiake information criterion indicates that the addition of the additional parameter does not improve the model signficantly (the Akaike criterion for model ml2 is higher than for model ml).
[9]:
# Create a model object by passing it the observed series
ml2 = ps.Model(gwdata)
# Add the recharge data as explanatory variable
ts1 = ps.StressModel2([precip, evap], ps.Gamma, name='rainevap', settings=("prec", "evap"))
ml2.add_stressmodel(ts1)
# Solve the model
ml2.solve()
# Plot the results
ml2.plot()
# Statistics
ml2.stats.summary()
INFO: Cannot determine frequency of series head.
INFO: Inferred frequency for time series rain: freq= D
INFO: Inferred frequency for time series evap: freq= D
Fit report head Fit Statistics
==================================================
nfev 20 EVP 92.92
nobs 644 R2 0.93
noise True RMSE 0.11
tmin 1985-11-14 00:00:00 AIC 7.73
tmax 2015-06-28 00:00:00 BIC 34.54
freq D Obj 2.01
warmup 3650 days 00:00:00 ___
solver LeastSquares Interpolated No
Parameters (6 were optimized)
==================================================
optimal stderr initial vary
rainevap_A 682.159632 ±5.23% 215.674528 True
rainevap_n 1.018176 ±1.78% 1.000000 True
rainevap_a 150.383444 ±7.48% 10.000000 True
rainevap_f -1.271777 ±4.77% -1.000000 True
constant_d 27.883096 ±0.24% 27.900078 True
noise_alpha 49.922165 ±11.87% 15.000000 True
Parameter correlations |rho| > 0.5
==================================================
rainevap_A rainevap_a 0.61
rainevap_n rainevap_a -0.77
rainevap_f 0.53
constant_d -0.52
rainevap_f constant_d -0.99
[9]:
| Value | |
|---|---|
| Statistic | |
| rmse | 0.114437 |
| rmsn | 0.079393 |
| sse | 8.439089 |
| mae | 0.090165 |
| nse | 0.929174 |
| evp | 92.917394 |
| rsq | 0.929069 |
| bic | 34.540444 |
| aic | 7.734251 |
Origin of the series¶
The rainfall data is taken from rainfall station Heibloem in The Netherlands.
The evaporation data is taken from weather station Maastricht in The Netherlands.
The head data is well B58C0698, which was obtained from Dino loket