Creating Equidistant Timeseries#
This notebooks shows functionality for creating equidistant timeseries in Pastas. This is sometimes useful or necessary, i.e. the Stoffer-Toloi test for autocorrelation requires an equidistant timeseries (that is allowed to have missing data).
Developed by D. Brakenhoff, Artesia, 2021
[1]:
import pastas as ps
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
ps.show_versions()
Python version: 3.10.8 (main, Oct 26 2022, 10:42:48) [GCC 11.2.0]
Numpy version: 1.23.5
Scipy version: 1.10.0
Pandas version: 1.5.2
Pastas version: 0.22.0
Matplotlib version: 3.6.2
We define 3 pandas methods for resampling to an equidistant timeseries.
The first takes a sample at equidistant timesteps from the original series, at the user-specified frequency.
The second creates a new equidistant index, rounded to the user-specified frequency. Then
Series.reindex()is used withmethod="nearest".The third method rounds the series index down to the nearest user-specified frequency, then drops the duplicates before calling
Series.asfreqwith the user-specified frequency. This ensures no duplicates are in the resulting timeseries.
Pastas contains the function pastas.utils.get_equidistant_timeseries() which does something similar, but attempts to minimize the number of dropped points and ensures that each observation from the original timeseries is used only once in the resulting equidistant timeseries.
Note:in terms of performance the pandas methods are undoubtedly faster.
[2]:
def pandas_sample(series, freq):
series = series.copy()
t_offset = ps.utils._get_time_offset(series.index, freq).value_counts().idxmax()
new_idx = pd.date_range(
series.index[0].floor(freq) + t_offset,
series.index[-1].floor(freq) + t_offset,
freq=freq
)
return series.reindex(new_idx)
def pandas_nearest(series, freq, tolerance=None):
series = series.copy()
# Create equidistant timeseries with Pandas
idx = pd.date_range(series.index[0].floor(freq),
series.index[-1].ceil(freq),
freq=freq)
spandas = series.reindex(idx, method="nearest", tolerance=tolerance)
return spandas
def pandas_asfreq(series, freq):
# Create equidistant timeseries with most frequent samples
series = series.copy()
series.index = series.index.floor(freq)
spandas = (series
.reset_index()
.drop_duplicates(subset="index", keep="first", inplace=False)
.set_index("index")
.asfreq(freq)
.squeeze()
)
return spandas
Example 1#
Lets create a timeseries spaced which is normally spaced with a frequency of 6 hours. The first and last measurement are shifted a bit later and earlier respectively. The two method compared here are the new function in Pastas and the Pandas reindex function.
[3]:
# Create timeseries
freq = "6H"
idx0 = pd.date_range("2000-01-01", freq=freq, periods=7).tolist()
idx0[0] = pd.Timestamp("2000-01-01 04:00:00")
idx0[-1] = pd.Timestamp("2000-01-02 11:00:00")
series = pd.Series(index=idx0, data=np.arange(len(idx0), dtype=float))
# Create equidistant timeseries with Pastas
s_pd1 = pandas_sample(series, freq)
s_pd2 = pandas_nearest(series, freq)
s_pd3 = pandas_asfreq(series, freq)
s_pastas = ps.utils.get_equidistant_series(series, freq)
# Create figure
plt.figure(figsize=(10, 4))
ax = series.plot(marker="o", label="original timeseries", ms=10,)
s_pd2.plot(ax=ax, marker="x", ms=8, label="pandas_nearest")
s_pd3.plot(ax=ax, marker="^", ms=8, label="pandas_asfreq")
s_pd1.plot(ax=ax, marker="+", ms=16, label="pandas_sample")
s_pastas.plot(ax=ax, marker=".", label="pastas equidistant")
ax.grid(b=True)
ax.legend(loc="best")
ax.set_xlabel("");
/tmp/ipykernel_3641/3339565909.py:21: MatplotlibDeprecationWarning: The 'b' parameter of grid() has been renamed 'visible' since Matplotlib 3.5; support for the old name will be dropped two minor releases later.
ax.grid(b=True)
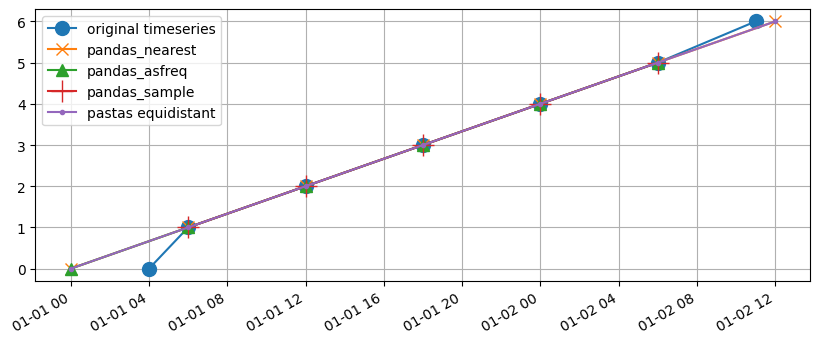
As we can see, both the pandas_nearest and pandas_asfreq methods and get_equidistant_series show the expected behavior. The data at the beginning and at the end is shifted to the nearest equidistant timestamp. The pandas_sample method drops 2 datapoints because they’re measured at different time offsets.
[4]:
dfall = pd.concat([series, s_pd1, s_pd2, s_pd3, s_pastas], axis=1)
dfall.columns = [
"original",
"pandas_sample",
"pandas_nearest",
"pandas_asfreq",
"pastas"
]
dfall
[4]:
| original | pandas_sample | pandas_nearest | pandas_asfreq | pastas | |
|---|---|---|---|---|---|
| 2000-01-01 00:00:00 | NaN | NaN | 0.0 | 0.0 | 0.0 |
| 2000-01-01 04:00:00 | 0.0 | NaN | NaN | NaN | NaN |
| 2000-01-01 06:00:00 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 2000-01-01 12:00:00 | 2.0 | 2.0 | 2.0 | 2.0 | 2.0 |
| 2000-01-01 18:00:00 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 |
| 2000-01-02 00:00:00 | 4.0 | 4.0 | 4.0 | 4.0 | 4.0 |
| 2000-01-02 06:00:00 | 5.0 | 5.0 | 5.0 | 5.0 | 5.0 |
| 2000-01-02 11:00:00 | 6.0 | NaN | NaN | NaN | NaN |
| 2000-01-02 12:00:00 | NaN | NaN | 6.0 | NaN | 6.0 |
Example 2#
[5]:
# Create timeseries
freq = "D"
idx0 = pd.date_range("2000-01-01", freq=freq, periods=7).tolist()
idx0[0] = pd.Timestamp("2000-01-01 09:00:00")
del idx0[2]
del idx0[2]
idx0[-2] = pd.Timestamp("2000-01-06 13:00:00")
idx0[-1] = pd.Timestamp("2000-01-06 23:00:00")
series = pd.Series(index=idx0, data=np.arange(len(idx0), dtype=float))
# Create equidistant timeseries
s_pd1 = pandas_sample(series, freq)
s_pd2 = pandas_nearest(series, freq)
s_pd3 = pandas_asfreq(series, freq)
s_pastas = ps.utils.get_equidistant_series(series, freq)
# Create figure
plt.figure(figsize=(10, 4))
ax = series.plot(marker="o", label="original", ms=10)
s_pd2.plot(ax=ax, marker="x", ms=10, label="pandas nearest")
s_pd3.plot(ax=ax, marker="^", ms=8, label="pandas asfreq")
s_pd1.plot(ax=ax, marker="+", ms=16, label="pandas sample")
s_pastas.plot(ax=ax, marker=".", label="equidistant")
ax.grid(b=True)
ax.legend(loc="best")
ax.set_xlabel("");
/tmp/ipykernel_3641/3351234055.py:24: MatplotlibDeprecationWarning: The 'b' parameter of grid() has been renamed 'visible' since Matplotlib 3.5; support for the old name will be dropped two minor releases later.
ax.grid(b=True)
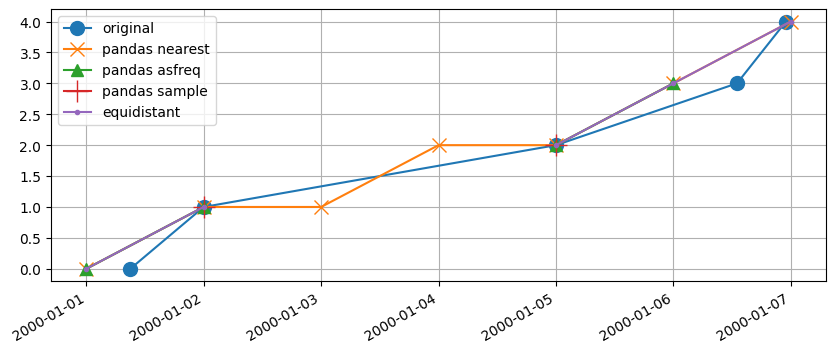
In this example, the shortcomings of pandas_nearest are clearly visible. It duplicates observations from the original timeseries to fill the gaps. This can be solved by passing e.g. tolerance="0.99{freq}" to series.reindex() in which case the gaps will not be filled. However, with very irregular timesteps this is not guaranteed to work and duplicates may still occur. The pandas_asfreq and pastas methods work as expected and use the available data to create a reasonable
equidistant timeseries from the original data. The pandas_sample method is only able to keep two observations from the original series in this example.
[6]:
dfall = pd.concat([series, s_pd1, s_pd2, s_pd3, s_pastas], axis=1)
dfall.columns = [
"original",
"pandas_sample",
"pandas_nearest",
"pandas_asfreq",
"pastas",
]
dfall
[6]:
| original | pandas_sample | pandas_nearest | pandas_asfreq | pastas | |
|---|---|---|---|---|---|
| 2000-01-01 00:00:00 | NaN | NaN | 0.0 | 0.0 | 0.0 |
| 2000-01-01 09:00:00 | 0.0 | NaN | NaN | NaN | NaN |
| 2000-01-02 00:00:00 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 2000-01-03 00:00:00 | NaN | NaN | 1.0 | NaN | NaN |
| 2000-01-04 00:00:00 | NaN | NaN | 2.0 | NaN | NaN |
| 2000-01-05 00:00:00 | 2.0 | 2.0 | 2.0 | 2.0 | 2.0 |
| 2000-01-06 00:00:00 | NaN | NaN | 3.0 | 3.0 | 3.0 |
| 2000-01-06 13:00:00 | 3.0 | NaN | NaN | NaN | NaN |
| 2000-01-06 23:00:00 | 4.0 | NaN | NaN | NaN | NaN |
| 2000-01-07 00:00:00 | NaN | NaN | 4.0 | NaN | 4.0 |
Example 3#
[7]:
# Create timeseries
freq = "2H"
freq2 = "1H"
idx0 = pd.date_range("2000-01-01 18:00:00", freq=freq, periods=3).tolist()
idx1 = pd.date_range("2000-01-02 01:30:00", freq=freq2, periods=10).tolist()
idx0 = idx0 + idx1
idx0[3] = pd.Timestamp("2000-01-02 01:31:00")
series = pd.Series(index=idx0, data=np.arange(len(idx0), dtype=float))
series.iloc[8:10] = np.nan
# Create equidistant timeseries
s_pd1 = pandas_sample(series, freq)
s_pd2 = pandas_nearest(series, freq)
s_pd3 = pandas_asfreq(series, freq)
s_pastas1 = ps.utils.get_equidistant_series(
series, freq, minimize_data_loss=True)
s_pastas2 = ps.utils.get_equidistant_series(
series, freq, minimize_data_loss=False)
# Create figure
plt.figure(figsize=(10, 6))
ax = series.plot(marker="o", label="original", ms=10)
s_pd2.plot(ax=ax, marker="x", ms=10, label="pandas nearest")
s_pd3.plot(ax=ax, marker="^", ms=8, label="pandas asfreq")
s_pd1.plot(ax=ax, marker="+", ms=16, label="pandas sample")
s_pastas1.plot(ax=ax, marker=".", ms=6, label="equidistant (minimize data loss)")
s_pastas2.plot(ax=ax, marker="+", ms=10, label="equidistant (default)")
ax.grid(b=True)
ax.legend(loc="best")
ax.set_xlabel("");
/tmp/ipykernel_3641/4196967257.py:30: MatplotlibDeprecationWarning: The 'b' parameter of grid() has been renamed 'visible' since Matplotlib 3.5; support for the old name will be dropped two minor releases later.
ax.grid(b=True)
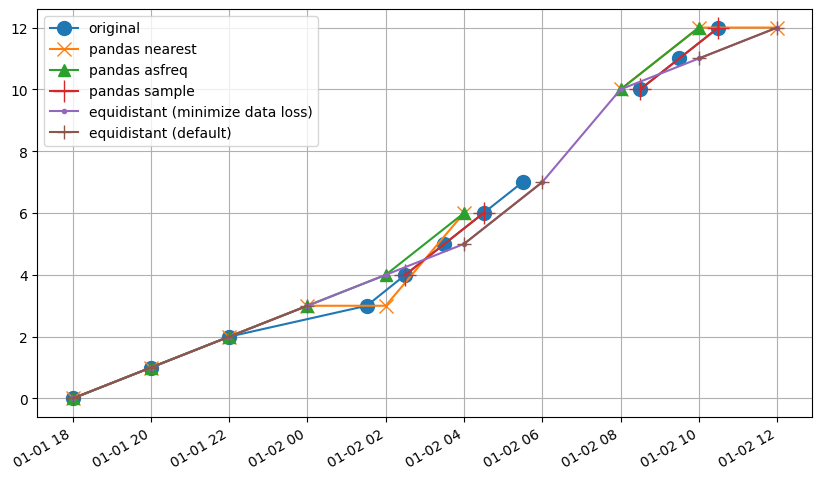
In this example we can observe the following behavior in each method: - pandas_sample retains 4 values. - pandas_nearest duplicates some observations in the equidistant timeseries. - pandas_asfreq does quite well, but drops some observations near the gap in the original timeseries. - the pastas method with the default option misses an observation right after the gap in the original timeseries. - the pastas method with minimize_data_loss=True fills this gap, using as much data as
possible from the original timeseries.
The results from the pandas_asfreq and pastas method are both good, but the pastas methods retains more of the original data.
[8]:
dfall = pd.concat([series, s_pd1, s_pd2, s_pd3, s_pastas2, s_pastas1], axis=1)
dfall.columns = [
"original",
"pandas_sample",
"pandas_nearest",
"pandas_asfreq",
"pastas (default)",
"pastas (minimize data loss)",
]
dfall
[8]:
| original | pandas_sample | pandas_nearest | pandas_asfreq | pastas (default) | pastas (minimize data loss) | |
|---|---|---|---|---|---|---|
| 2000-01-01 18:00:00 | 0.0 | NaN | 0.0 | 0.0 | 0.0 | 0.0 |
| 2000-01-01 18:30:00 | NaN | NaN | NaN | NaN | NaN | NaN |
| 2000-01-01 20:00:00 | 1.0 | NaN | 1.0 | 1.0 | 1.0 | 1.0 |
| 2000-01-01 20:30:00 | NaN | NaN | NaN | NaN | NaN | NaN |
| 2000-01-01 22:00:00 | 2.0 | NaN | 2.0 | 2.0 | 2.0 | 2.0 |
| 2000-01-01 22:30:00 | NaN | NaN | NaN | NaN | NaN | NaN |
| 2000-01-02 00:00:00 | NaN | NaN | 3.0 | 3.0 | 3.0 | 3.0 |
| 2000-01-02 00:30:00 | NaN | NaN | NaN | NaN | NaN | NaN |
| 2000-01-02 01:31:00 | 3.0 | NaN | NaN | NaN | NaN | NaN |
| 2000-01-02 02:00:00 | NaN | NaN | 3.0 | 4.0 | NaN | 4.0 |
| 2000-01-02 02:30:00 | 4.0 | 4.0 | NaN | NaN | NaN | NaN |
| 2000-01-02 03:30:00 | 5.0 | NaN | NaN | NaN | NaN | NaN |
| 2000-01-02 04:00:00 | NaN | NaN | 6.0 | 6.0 | 5.0 | 5.0 |
| 2000-01-02 04:30:00 | 6.0 | 6.0 | NaN | NaN | NaN | NaN |
| 2000-01-02 05:30:00 | 7.0 | NaN | NaN | NaN | NaN | NaN |
| 2000-01-02 06:00:00 | NaN | NaN | NaN | NaN | 7.0 | 7.0 |
| 2000-01-02 06:30:00 | NaN | NaN | NaN | NaN | NaN | NaN |
| 2000-01-02 07:30:00 | NaN | NaN | NaN | NaN | NaN | NaN |
| 2000-01-02 08:00:00 | NaN | NaN | 10.0 | 10.0 | NaN | 10.0 |
| 2000-01-02 08:30:00 | 10.0 | 10.0 | NaN | NaN | NaN | NaN |
| 2000-01-02 09:30:00 | 11.0 | NaN | NaN | NaN | NaN | NaN |
| 2000-01-02 10:00:00 | NaN | NaN | 12.0 | 12.0 | 11.0 | 11.0 |
| 2000-01-02 10:30:00 | 12.0 | 12.0 | NaN | NaN | NaN | NaN |
| 2000-01-02 12:00:00 | NaN | NaN | 12.0 | NaN | 12.0 | 12.0 |
Example 4#
[9]:
# Create timeseries
freq = "2H"
freq2 = "1H"
idx0 = pd.date_range("2000-01-01 18:00:00", freq=freq, periods=3).tolist()
idx1 = pd.date_range("2000-01-02 00:00:00", freq=freq2, periods=10).tolist()
idx0 = idx0 + idx1
series = pd.Series(index=idx0, data=np.arange(len(idx0), dtype=float))
series.iloc[8:10] = np.nan
# Create equidistant timeseries
s_pd1 = pandas_sample(series, freq)
s_pd2 = pandas_nearest(series, freq)
s_pd3 = pandas_asfreq(series, freq)
s_pastas1 = ps.utils.get_equidistant_series(
series, freq, minimize_data_loss=True)
s_pastas2 = ps.utils.get_equidistant_series(
series, freq, minimize_data_loss=False)
# Create figure
plt.figure(figsize=(10, 6))
ax = series.plot(marker="o", label="original", ms=10)
s_pd2.plot(ax=ax, marker="x", ms=10, label="pandas nearest")
s_pd3.plot(ax=ax, marker="^", ms=8, label="pandas asfreq")
s_pd1.plot(ax=ax, marker="+", ms=16, label="pandas sample")
s_pastas1.plot(ax=ax, marker=".", ms=6,
label="equidistant (minimize data loss)")
s_pastas2.plot(ax=ax, marker="+", ms=10, label="equidistant (default)")
ax.grid(b=True)
ax.legend(loc="best")
ax.set_xlabel("")
/tmp/ipykernel_3641/1043924654.py:28: MatplotlibDeprecationWarning: The 'b' parameter of grid() has been renamed 'visible' since Matplotlib 3.5; support for the old name will be dropped two minor releases later.
ax.grid(b=True)
[9]:
Text(0.5, 0, '')
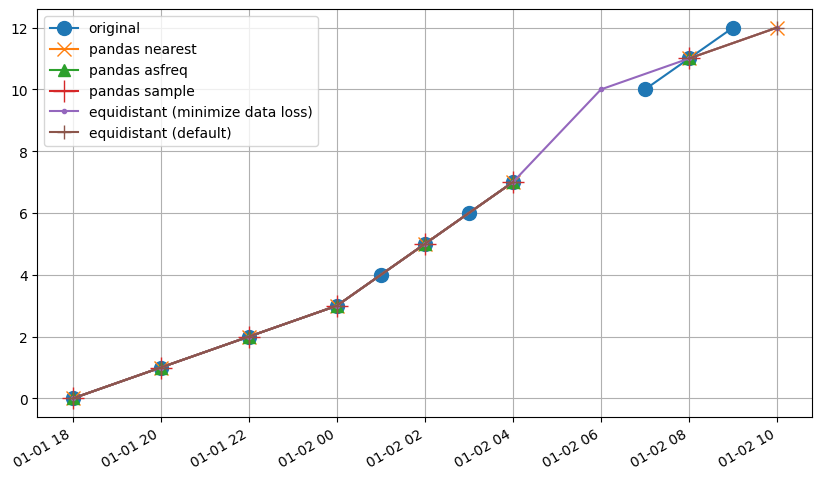
Similar to the previous example, the pastas method retains the most data from the original timeseries. In this case both pandas methods perform well, but do omit some of the original data at the end of the timeseries or near the gap in the original timeseries.
[10]:
dfall = pd.concat([series, s_pd1, s_pd2, s_pd3, s_pastas2, s_pastas1], axis=1)
dfall.columns = [
"original",
"pandas_sample",
"pandas_nearest",
"pandas_asfreq",
"pastas (default)",
"pastas (minimize data loss)",
]
dfall
[10]:
| original | pandas_sample | pandas_nearest | pandas_asfreq | pastas (default) | pastas (minimize data loss) | |
|---|---|---|---|---|---|---|
| 2000-01-01 18:00:00 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2000-01-01 20:00:00 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 2000-01-01 22:00:00 | 2.0 | 2.0 | 2.0 | 2.0 | 2.0 | 2.0 |
| 2000-01-02 00:00:00 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 |
| 2000-01-02 01:00:00 | 4.0 | NaN | NaN | NaN | NaN | NaN |
| 2000-01-02 02:00:00 | 5.0 | 5.0 | 5.0 | 5.0 | 5.0 | 5.0 |
| 2000-01-02 03:00:00 | 6.0 | NaN | NaN | NaN | NaN | NaN |
| 2000-01-02 04:00:00 | 7.0 | 7.0 | 7.0 | 7.0 | 7.0 | 7.0 |
| 2000-01-02 05:00:00 | NaN | NaN | NaN | NaN | NaN | NaN |
| 2000-01-02 06:00:00 | NaN | NaN | NaN | NaN | NaN | 10.0 |
| 2000-01-02 07:00:00 | 10.0 | NaN | NaN | NaN | NaN | NaN |
| 2000-01-02 08:00:00 | 11.0 | 11.0 | 11.0 | 11.0 | 11.0 | 11.0 |
| 2000-01-02 09:00:00 | 12.0 | NaN | NaN | NaN | NaN | NaN |
| 2000-01-02 10:00:00 | NaN | NaN | 12.0 | NaN | 12.0 | 12.0 |