Time series in Pastas#
Time series are at the heart of Pastas and modeling hydraulic head fluctuations. In this section background information is provided on important characteristics of time series and how these may influence your modeling results.
Different types of time series#
Regular and irregular time series#
Time series data are a set of data values measured at certain times, ordered in a way that the time indices are increasing. Many time series analysis and modeling methods require that the time step between the measurements is always the same or in other words, equidistant. Such regular time series may have missing data, but those may be filled so that computations can be done with a constant time step. Hydraulic heads are often measured at irregular time intervals; such time series are called irregular. This is especially true for historic time series that were measured by hand. The figure below graphically shows the difference between the three types of time series.
/tmp/ipykernel_2071/611205993.py:7: Pandas4Warning: 'H' is deprecated and will be removed in a future version. Please use 'h' instead of 'H'.
index = [t + pd.Timedelta(np.random.rand() * 24, unit="H") for t in missing_data.index]
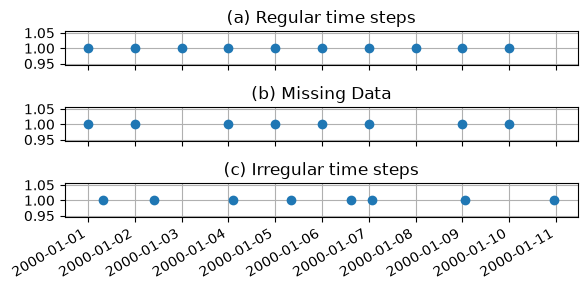
Independent and dependent time series#
We can differentiate between two types of input time series for Pastas models: the dependent and independent time series. The dependent time series are those that we want to explain/model (e.g., the groundwater levels), and are referred to as the oseries in pastas (short for observation series). The independent time series are those that we use to model the dependent time series (e.g., precipitation or evaporation), and are referred to as stresses in Pastas. The requirements for these time series are different:
The dependent time series may be of any kind: regular, missing data or irregular.
The stress time series must have regular time steps.
A word on timestamps and measurements#
Stresses often represent a flux measured over a certain time period. For example, precipitation is often provided in mm/day, and the value represents the cumulative precipitation amount for a day. This is recorded at the end of the day, e.g., a measurement with a time stamp of 2000-01-01 represents the total precipitation that fell on the first of January in the year 2000.
The Python package for time series data: pandas#
The pandas package provides a lot of methods to deal with time series data, such as resampling, gap-filling, and computing descriptive statistics. Another important functionality of pandas are the pandas.read_csv and related methods, which facilitate the loading of data from csv-files and other popular data storage formats. Pastas requires all time series to be provided as pandas.Series with a pandas.DatetimeIndex; examples are provided. For more information and user guidance on pandas please see their documentation website (https://pandas.pydata.org).
Validating user-provided time series#
As is clear from the descriptions above, the user is required to provide time series in a certain format and with certain characteristics, depending on the type of time series. To prevent issues later in the modeling chain, all user-provided time series are internally checked to make sure all requirements are met. This is done using the pastas.validate_stress and pastas.validate_oseries methods, which can also be called directly by the user. Let’s look at the docstring of these methods to see what is checked:
?ps.validate_stress
The last check (equidistant time steps) is not required for oseries. If any of these checks fail, the pastas.validate_stress and pastas.validate_oseries methods will return an Error with pointers on how to solve the problem and fix the time series. We refer to the Examples-section for more examples on how to pre-process the user-provided time series.
Settings for user-provided time series#
User-provided time series must be long enough and of the right frequency. If this is not the case, Pastas will adjust the provided time series. Internally, time series are stored in a pastas.TimeSeries object, which has functions to extend the time series forward and backward in time (when needed) and/or resample the time series to a different frequency (when needed). How these two operations are performed depends on the settings that are provided. An appropriate setting must be specified when creating a StressModel object.
For example, specify the setting as prec for a StressModel that simulates the effect of precipitation. The predefined settings and their associated operations can be accessed through ps.rcParams["timeseries"] (see code cell below). It can be seen, for example, that when the setting is prec (precipitation), a missing value is replaced by the value zero (fill_nan=0.0 in the table) and when the series has to be extended in the past, it is filled with the mean value of the provided series (fill_before=mean in the table).
pd.DataFrame.from_dict(ps.timeseries.settings)
| oseries | prec | evap | well | waterlevel | level | flux | quantity | |
|---|---|---|---|---|---|---|---|---|
| fill_nan | drop | 0.0 | interpolate | 0.0 | interpolate | interpolate | 0.0 | 0.0 |
| sample_down | drop | mean | mean | mean | mean | mean | mean | sum |
| sample_up | NaN | bfill | bfill | bfill | interpolate | interpolate | bfill | divide |
| fill_before | NaN | mean | mean | 0.0 | mean | mean | mean | mean |
| fill_after | NaN | mean | mean | 0.0 | mean | mean | mean | mean |
Each column name is a valid option for the settings argument. For example, the default setting for the precipitation stress provided to the ps.RechargeModel object is “prec” (see the docstring of ps.RechargeModel). This means that the following settings is used:
ps.timeseries.settings["prec"]
# sm = ps.Stressmodel(stress, settings="prec")
{'sample_up': 'bfill',
'sample_down': 'mean',
'fill_nan': 0.0,
'fill_before': 'mean',
'fill_after': 'mean'}
Alternatively, one may provide a dictionary to a stress model object with the settings.
settings = {
"fill_before": 0.0,
"fill_after": 0.0,
# Etcetera
}
# sm = ps.Stressmodel(stress, settings=settings)
If Pastas does an operation on the time series that is provided by the user, it will always output an INFO message describing what is done. To see these, make sure the log_level of Pastas is set to “INFO” by running ps.set_log_level("INFO") before.
Formal requirements time series#
The formal requirements for a time series are listed below. When using, for example, pandas.read_csv correctly, these requirements are automatically met.
The dtype for a date must be
pandas.Timestamp.The dtype for a sequence of dates must be
pandas.DatetimeIndexwithpandas.Timestamps.The dtype for a time series must be a
pandas.Serieswith apandas.DatetimeIndex.The dtype for the values of a
pandas.Seriesmust befloat.