Modeling with different timesteps#
Developed by D.A. Brakenhoff, Artesia
This notebooks contains examples how to model with different timesteps, e.g. 14-day and hourly.
The difference between the model timestep and the observation frequency#
The model timestep is the time interval on which the heads are simulated by the Pastas model. The observation frequency is the time interval between two head observations. By default Pastas uses a daily modeling timestep, whereas the timestep between observations can vary:
If the observation frequency is higher (e.g. hourly) Pastas will take a daily sample of head observations to fit the model.
If the observation frequency is lower (e.g. weekly), Pastas will calibrate the model on those weekly observations.
The observation frequency can even be irregular, meaning that the timestep between two observations does not have to be constant.
In this notebook we’re showing how to use Pastas to model with different timesteps. The observation frequency is related to this choice, but does not have to be the same as the modeling timestep.
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import pastas as ps
ps.show_versions()
ps.logger.setLevel("ERROR")
Pastas : 2.0.0
Python : 3.14.6
Numpy : 2.4.6
Pandas : 3.0.5
Scipy : 1.18.0
Matplotlib : 3.11.1
Numba : 0.66.0
Before we get to the modeling, we define a helper function to generate synthetic heads using an input stress and a response function with known parameters.
def generate_synthetic_heads(
input,
rfunc,
params,
cutoff=0.9999,
dt=1.0,
constant=0.0,
noise="none",
sigma_n=0.1,
alpha=2.0,
):
# Generate the head
step = rfunc.block(params, cutoff=cutoff, dt=dt)
h = constant * np.ones(len(input) + step.size)
for i in range(len(input)):
h[i : i + step.size] += input.iloc[i] * step
head = pd.Series(
index=input.index,
data=h[: len(input)],
)
# add correlated noise AR(1)
if noise == "correlated":
delt = (head.index[1:] - head.index[:-1]).values / pd.Timedelta("1d")
noise = sigma_n * np.random.randn(len(head))
residuals = np.zeros_like(noise)
residuals[0] = noise[0]
for i in range(1, head.index.size):
residuals[i] = np.exp(-delt[i - 1] / alpha) * residuals[i - 1] + noise[i]
head = head + residuals
return head
A model with a 14-day timestep#
In this example we generate heads from measured precipitation and evaporation using a known response function. Next we take a sample from the synthetically generated heads with one observation every 14 days. Then we build 3 pastas models:
Model with daily timestep
Model with 14-day timestep, where we let pastas resample the stresses.
Model with 14-day timestep, where we use manually resampled stresses.
The three Pastas models are expected to give very similar results.
First we read in some real precipitation and evaporation data.
prec = pd.read_csv(
"../../doc/examples/data/rain_260.csv", index_col=[0], parse_dates=True
).squeeze()
evap = pd.read_csv(
"../../doc/examples/data/evap_260.csv", index_col=[0], parse_dates=True
).squeeze()
Define a response function and its parameters.
rfunc = ps.Exponential()
Atrue = 0.8
atrue = 50
ftrue = -1.3 # evaporation factor
constant = 20 # constant level
params = [Atrue, atrue]
Calculate effective precipitation using a linear recharge model with
evaporation factor f. Use this stress to generate a synthetic head time
series.
stress = prec + ftrue * evap
head = generate_synthetic_heads(stress, rfunc, params, constant=constant)
head = head.loc["1990":"2015"]
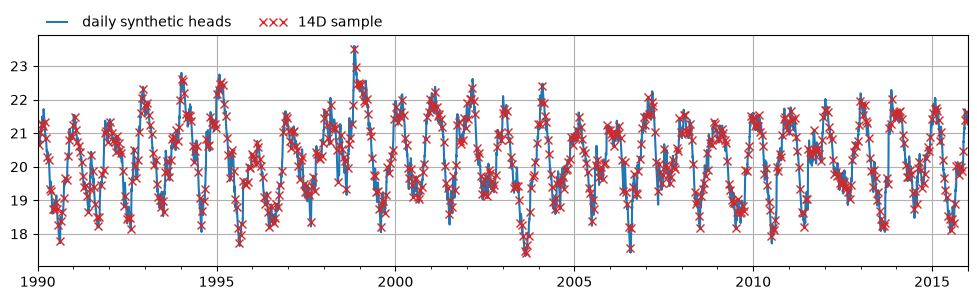
Take a sample from the heads with one observation every 2 weeks.
sample_step = 14
freq = f"{sample_step}D"
sample = head.iloc[::sample_step].asfreq(freq)
Plot synthetic head time series.
ax = head.plot(figsize=(12, 3), label="daily synthetic heads")
sample.plot(ax=ax, marker="x", color="C3", ls="none", label=f"{freq} sample")
ax.legend(loc=(0, 1), frameon=False, ncol=2, numpoints=3)
ax.grid(True)
Manually resample stresses to a two-weekly frequency. We take the mean to
ensure the resulting parameters estimated by the pastas model have the same
units. (If we took the sum, we would have to divide the gain recharge_A by
the number of days in our period, in this case 14.) Using this method we can
ensure the stresses align with the heads sample. The mean precipitation and
evaporation are calculated over the two week periods prior to each head
observation.
p_resampled = prec.resample(freq, closed="right", label="right").mean()
e_resampled = evap.resample(freq, closed="right", label="right").mean()
Now we create three pastas models and fit them on the heads sample.
Model 1 uses a daily timestep.
Model 2 uses a 14-day timestep, and lets Pastas do the resampling.
Model 3 uses a 14-day timestep, and uses our manually resampled stresses.
How do we get Pastas to use a 14-day timestep? This is done by supplying the
freq keyword argument to the Model, e.g.:
ps.Model(head, freq="14D")
# model 1: daily timestep
ml_01D = ps.Model(sample, name="01D")
ps.RechargeModel(ml_01D, prec, evap, rfunc=rfunc, name="recharge")
ml_01D.solve(report=False)
# model 2: 14D timestep, let pastas resample stresses with daily freq to 14D
ml_14D_ps = ps.Model(sample, name=f"{freq}_ps", freq=freq)
ps.RechargeModel(ml_14D_ps, prec, evap, rfunc=rfunc, name="recharge")
ml_14D_ps.solve(report=False)
# model 3: 14D timestep, use manually resampled stresses from daily to 14D
ml_14D = ps.Model(sample, name=freq, freq=freq)
ps.RechargeModel(ml_14D, p_resampled, e_resampled, rfunc=rfunc, name="recharge")
ml_14D.solve(report=False)
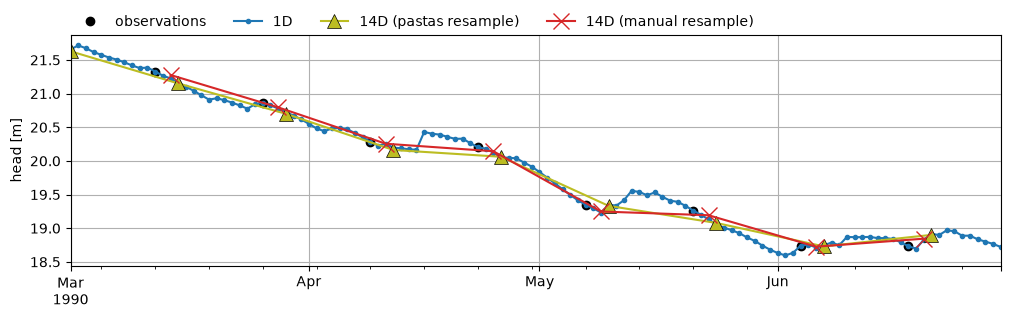
Visually compare the results of the three models for the period between March and June in 1990.
fig, ax = plt.subplots(1, 1, figsize=(12, 3))
sample.loc["1990-03":"1990-06"].plot(
ax=ax, linestyle="none", marker="o", color="k", label="observations"
)
ml_01D.simulate().loc["1990-03":"1990-06"].plot(ax=ax, marker=".", label="1D")
ml_14D_ps.simulate().loc["1990-03":"1990-06"].plot(
ax=ax,
marker="^",
ms=10,
mec="k",
mew=0.5,
c="C8",
label=f"{freq} (pastas resample)",
)
ml_14D.simulate().loc["1990-03":"1990-06"].plot(
ax=ax, marker="x", ms=12, c="C3", label=f"{freq} (manual resample)"
)
ax.legend(loc=(0, 1), frameon=False, ncol=4)
ax.set_ylabel("head [m]")
ax.grid(True)
As expected the fit for each of the models is equal or very close to 1.0.
comparison = ps.CompareModels([ml_01D, ml_14D_ps, ml_14D])
fit = comparison.get_metrics(metric_selection=["rsq"]).T
fit.index.name = "Model"
fit.round(3)
| rsq | |
|---|---|
| Model | |
| 01D | 1.000 |
| 14D_ps | 0.985 |
| 14D | 0.990 |
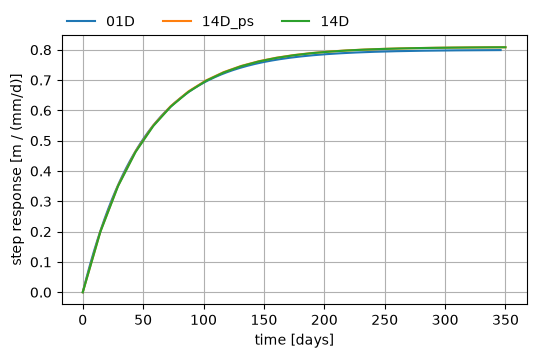
ax = comparison.plot_response()
ax.figure.set_figheight(3.5)
ax.figure.set_figwidth(6)
handles, _ = ax.get_legend_handles_labels()
ax.legend(
handles, [iml.name for iml in comparison.models], loc=(0, 1), frameon=False, ncol=3
)
ax.set_ylabel("step response [m / (mm/d)]")
ax.set_xlabel("time [days]")
ax.grid(True)
And let’s take a look at the estimated parameters and the true values.
dfparams = comparison.get_parameters()
dfparams["True values"] = params + [ftrue, constant]
dfparams.round(3)
| 01D | 14D_ps | 14D | True values | |
|---|---|---|---|---|
| recharge_A | 0.800 | 0.809 | 0.809 | 0.8 |
| recharge_a | 49.964 | 49.178 | 49.492 | 50.0 |
| recharge_f | -1.301 | -1.293 | -1.292 | -1.3 |
| constant_d | 20.002 | 19.989 | 19.987 | 20.0 |
Note that these differences are expected. The daily model is able to almost perfectly simulate the heads because the heads were also generated on a daily basis. The Pastas resampled model performs worst, since it is calibrating the model on interpolated observations, which is obviously a slightly different time series than the original heads sample. This happens because Pastas resamples the stresses in such a way that they do not align with the timing of the head observations. When we manually resample, we can ensure the indices between the stresses and the observations match, and we see that the fit and the parameters are nearly identical to the model with a daily timestep. A small difference remains because the 14-day model cannot account for the timing of the rainfall within a 14-day period. The generated heads are different if all precipitation falls at the beginning of the two-week period as compared to all rainfall falling at the end of the two-week period.
Hourly models#
A higher temporal resolution is sometimes necessary when head changes occur quickly, for example, heads that are affected by tidal fluctuations or the drawdown during pumping tests.
Tidal example#
In this first example we’ll generate a synthetic heads timeseries based on tidal fluctuations. These tidal fluctuations follow a simple sine wave with a period of 12 hours and 25 minutes.
Atide = 1.5 # tidal amplitude
# sine with period 12 hrs 25 minutes
t_idx = pd.date_range(head.index[0], head.index[-1] + pd.Timedelta(hours=23), freq="h")
tides = pd.Series(
index=t_idx,
data=Atide * np.sin(2 * np.pi * np.arange(t_idx.size) / (0.517375)),
)
Next we define a response function and its parameters to convert the tidal fluctuations into a synthetic head time series.
rf_tide = ps.Exponential()
A_tide = 1.0
a_tide = 0.15
Apply the response function and its parameters to our tidal stress to generate the synthetic heads.
ht = generate_synthetic_heads(tides, rf_tide, (A_tide, a_tide), dt=1 / 24.0)
htsel = ht.loc["2000-01-01":"2005-12-31"]
Plot the tidal stress and the resulting head.
ax = tides.loc["2000-01-01":"2000-01-02"].plot(figsize=(12, 3), label="sea level")
htsel.loc["2000-01-01":"2000-01-02"].plot(ax=ax, label="synthetic head")
ax.legend(loc=(0, 1), frameon=False, ncol=2)
ax.set_ylabel("[m]")
ax.grid(True)
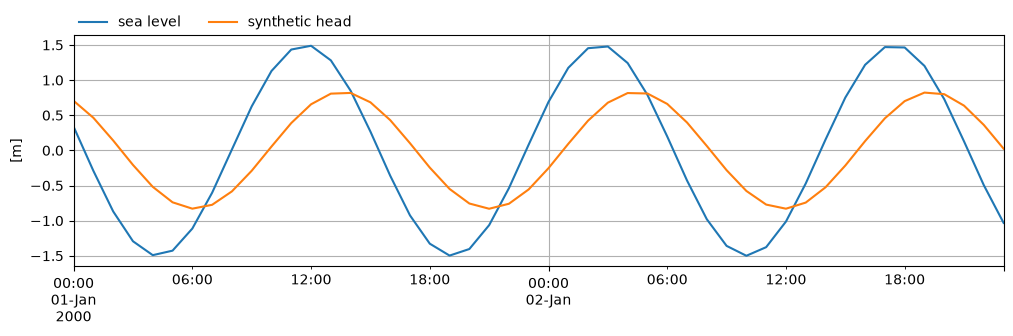
Next we build two Pastas models to simulate the head between 2000 and 2005. One model has a daily timestep and the other an hourly timestep.
The warmup period:
Note that Pastas selects a 10-year warmup period by default. This means internally the model will simulate the head between 1990 and 2005 to ensure the model has reached a steady-state and is not affected by the initial conditions. For smaller modeling timesteps, this longer warmup might cause the simulation to slow down (i.e. 10 years on an hourly timestep means 87600 head values are computed). Whether it is appropriate to shorten the response depends on the stresses and the response of the head to those stresses (which are usually not known prior to modeling the heads), but if calculation times are long, it could be worth exploring shortening the warmup. For extremely slow responses, a longer warmup period might also be appropriate.
In the calculation below we show how to set the warmup to 100 days two different ways, since we know our response is fast we don’t need the 10-year spin-up period.
# model with daily timestep
ml_D = ps.Model(htsel, name="daily", freq="D")
sm = ps.StressModel(
ml_D,
tides.loc["1995":"2005"],
rfunc=ps.Exponential(),
name="sealvl",
settings="waterlevel",
)
ml_D.settings["warmup"] = pd.Timedelta(days=100) # set warmup as pd.Timedelta
ml_D.solve(report=False)
# model with hourly timestep
ml_H = ps.Model(htsel, name="hourly", freq="h")
sm = ps.StressModel(
ml_H,
tides.loc["1995":"2005"],
rfunc=ps.Exponential(),
name="sealvl",
settings="waterlevel",
)
ml_H.solve(report=False, warmup=100) # in solve warmup is entered in days
If we look at the R² value of both models we can see that the daily model is performing poorly.
comp = ps.CompareModels([ml_D, ml_H])
comp.get_metrics(metric_selection=["rsq"]).round(3)
| daily | hourly | |
|---|---|---|
| rsq | 0.699 | 1.0 |
A glance at the estimated parameters, as compared to the true values of the parameters, shows that, as the fit statiscs suggest, the daily model is not able to estimate the parameters well.
dfparams = comp.get_parameters()
dfparams["True values"] = [A_tide, a_tide, 0.0]
dfparams.round(3)
| daily | hourly | True values | |
|---|---|---|---|
| sealvl_A | 88.406 | 0.998 | 1.00 |
| sealvl_a | 19.109 | 0.150 | 0.15 |
| constant_d | 0.000 | -0.000 | 0.00 |
Plotting comparisons between the observations and the simulations for both models shows that the daily model is not able to match the observations, whereas the hourly model is perfectly able to simulate the tidal fluctuations. This is what we would expect, the daily model simply does not contain sufficient information in the heads to allow the model to find the true parameters of the response function.
fig, (axd, axh) = plt.subplots(2, 1, figsize=(12, 6))
htsel.loc["2000-03-01":"2000-03-10"].plot(
ax=axh, linestyle="none", marker="o", color="k", label="observations"
)
ml_D.observations().loc["2000-03-01":"2000-03-10"].plot(
ax=axd, linestyle="none", marker="o", color="k", label="observations"
)
ml_D.simulate().loc["2000-03-01":"2000-03-10"].plot(
ax=axd, marker="^", color="C3", label="daily"
)
ml_H.simulate().loc["2000-03-01":"2000-03-10"].plot(
ax=axh, marker=".", c="C8", label="hourly"
)
for iax in (axd, axh):
iax.legend(loc=(0, 1), frameon=False, ncol=4)
iax.set_ylabel("head [m]")
iax.grid(True)
fig.tight_layout()
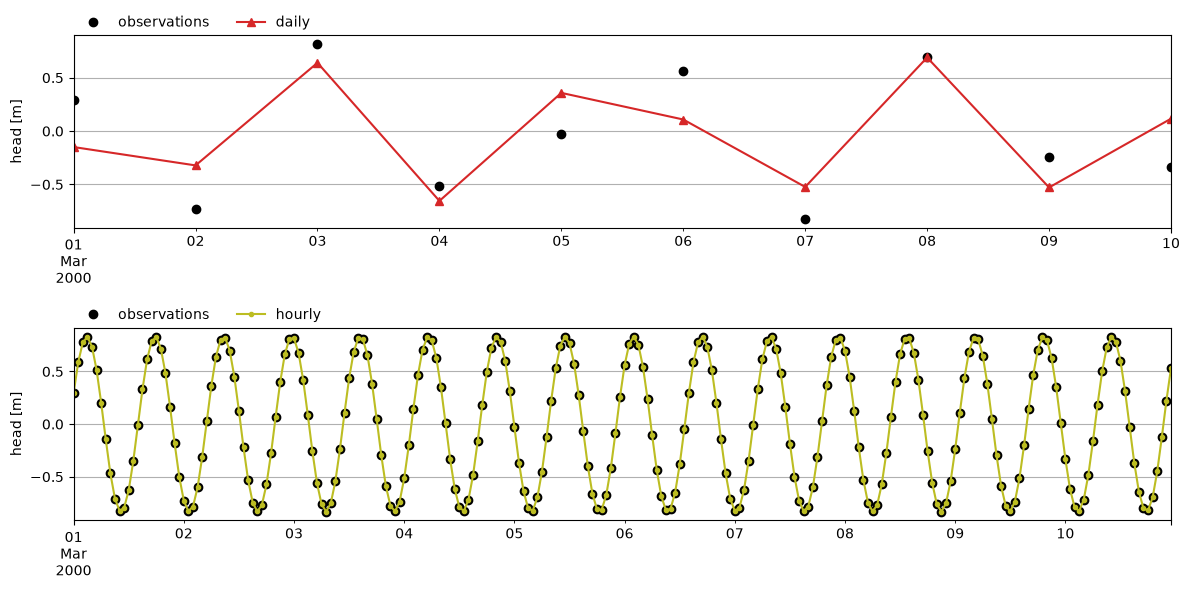
Pumping test#
In this example we will generate a synthetic time series that is influenced by both recharge and a pumping test.
First we start by loading some hourly precipitation and evaporation data from a weather station in the Netherlands.
# get hourly precipitation
prec = pd.read_csv(
"./data/vlissingen_prec_hourly.csv", index_col=[0], parse_dates=True
).squeeze()
# get hourly evaporation
evap = pd.read_csv(
"./data/vlissingen_evap_hourly.csv", index_col=[0], parse_dates=True
).squeeze()
The well for the pumping test discharge 100 m³/h between October 1, 2022 till October 31, 2022. We define a time series for the discharge of the well.
qw = pd.Series(index=pd.date_range("2022-09-30", "2022-11-30", freq="10min"), data=0)
qw.loc["2022-10"] = 100 * 24.0
Next we define two response functions, one for the recharge, and the other for the pumping well. These are used to generate a synthetic head time series.
# response for recharge
rf_rch = ps.Exponential()
A_rch = 5e3
a_rch = 10.0
f_rch = -1.1
# response for pumping well
rf_well = ps.Hantush()
A_well = -2e-4
a_well = 0.2
b_well = 0.1
We calculate the head contributions of each stress and add them together to create a synthetic head time series. For the recharge we generate an hourly head time series. For the pumping well we use a 10-minute timestep, which we resample to an hourly time series to add the two together.
# calculate precipitation excess
pe = prec + f_rch * evap
# generate head contributions of each stress
h_rch = generate_synthetic_heads(pe, rf_rch, (A_rch, a_rch), dt=1 / 24.0)
h_well = generate_synthetic_heads(
qw, rf_well, (A_well, a_well, b_well), dt=1 / (24.0 * 6)
)
# add time series to generate synthetic heads with freq="H"
head = h_rch + h_well.reindex(h_rch.index).fillna(0.0)
Plotting the resulting synthetic heads (with and without pumping).
ax = head.loc["2022"].plot(label="with pumping", figsize=(12, 3))
h_rch.loc["2022"].plot(label="without pumping")
ax.legend(loc=(0, 1), frameon=False, ncol=2)
ax.grid(True)
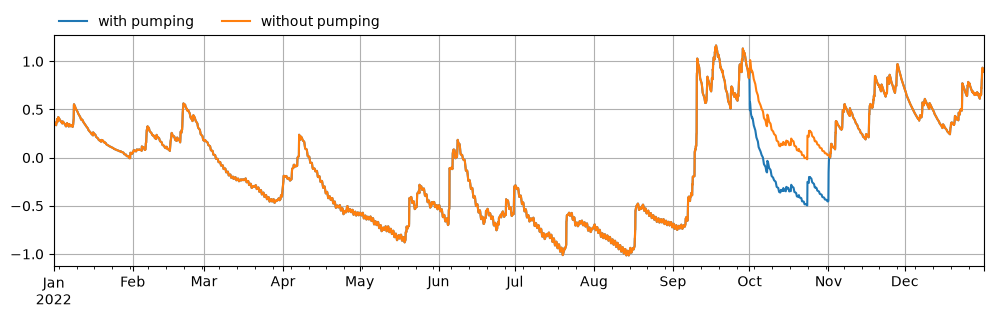
The effect of resampling the drawdown of the well with hourly and daily timesteps is shown below. The daily time series (black x’s) has no data points in the early stages of the pumping or recovery tests, and only contains information about the steady state drawdown. The hourly time series (red dots) has a few data points in the period when the head is changing as a result of the well turning on or off. This shows why modeling on an hourly timestep might be preferable in this situation.
ax = h_well.plot(figsize=(12, 3), label="10min")
h_well_h = ps.ts.pandas_equidistant_sample(h_well, "h")
h_well_d = ps.ts.pandas_equidistant_sample(h_well, "d")
h_well_h.plot(ax=ax, marker=".", ls="none", color="C3", label="h")
h_well_d.plot(ax=ax, marker="x", ls="none", color="k", label="d")
ax.legend(loc=(0, 1), frameon=False, ncol=3, numpoints=3)
ax.set_ylabel("head change [m]")
ax.grid(True)
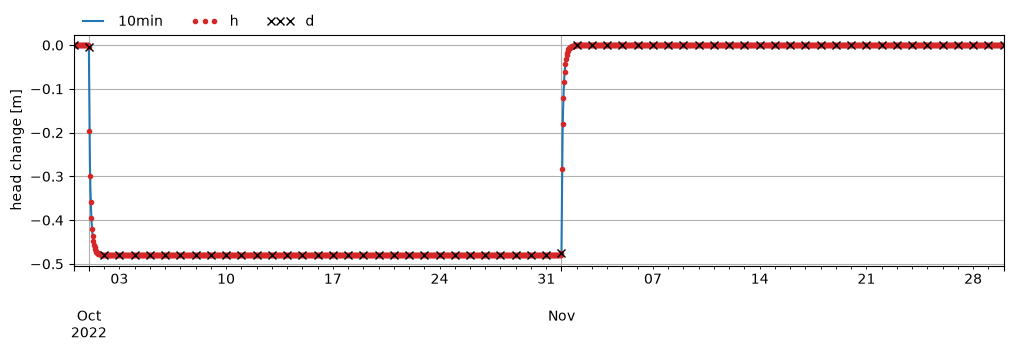
We defined our pumping time series on a 10-minute interval, but for modeling
with freq=”H” we want an hourly stress. We resample the original time series to
hourly using ps.ts.time_weighted_resample.
qw_h = ps.ts.time_weighted_resample(qw, tindex=h_rch.index).fillna(0.0)
Next we build two Pastas models, one with freq="H"and one with freq="D". We
don’t adjust the heads or any of the stresses for the daily model, and just let
Pastas take care of the resampling for us.
Here we once again shorten the warmup from the default 10 years to 1 year to speed up the simulation time (especially for the hourly model). From the response functions defined above, we know that 1 year is plenty. The \(t_{99.9}\) of the response can be calculated with:
t_99_9 = rf_rch.get_tmax([A_rch, a_rch], cutoff=0.999)
print(f"The t_99.9 of the response to recharge = {t_99_9:.1f} days")
The t_99.9 of the response to recharge = 69.1 days
# hourly model
ml_h = ps.Model(head, name="h", freq="h")
rm = ps.RechargeModel(ml_h, prec, evap, rfunc=ps.Exponential(), name="recharge")
wm = ps.StressModel(
ml_h, qw_h, rfunc=ps.Hantush(), name="well", settings="well", up=False
)
ml_h.solve(report=False, fit_constant=False, warmup=365)
# daily model
ml_d = ps.Model(head, name="d", freq="d")
rm = ps.RechargeModel(ml_d, prec, evap, rfunc=ps.Exponential(), name="recharge")
wm = ps.StressModel(
ml_d, qw_h, rfunc=ps.Hantush(), name="well", settings="well", up=False
)
ml_d.solve(report=False, fit_constant=False, warmup=365)
Let’s take a look at the R² for both models. Both models fit pretty much perfectly with the data.
c = ps.CompareModels([ml_d, ml_h])
c.get_metrics(metric_selection=["rsq"]).round(5)
| d | h | |
|---|---|---|
| rsq | 0.99992 | 0.99999 |
Comparing the observations and the two model results around the time of the pumping test shows that both models perform well, though the daily model does show a little less detail, for obvious reasons.
tmin = "2022-09-25"
tmax = "2022-11-15"
fig, ax = plt.subplots(1, 1, figsize=(12, 3))
sim_h = ml_h.simulate(tmin=tmin, tmax=tmax)
sim_d = ml_d.simulate(tmin=tmin, tmax=tmax)
head.loc[tmin:tmax].plot(
ax=ax, marker=".", color="k", ls="none", ms=3, label="observations"
)
sim_h.plot(ax=ax, label="hourly model")
sim_d.plot(ax=ax, label="daily model", color="C3", ls="dashed")
ax.legend(loc=(0, 1), frameon=False, ncol=3, numpoints=3)
ax.grid(True)
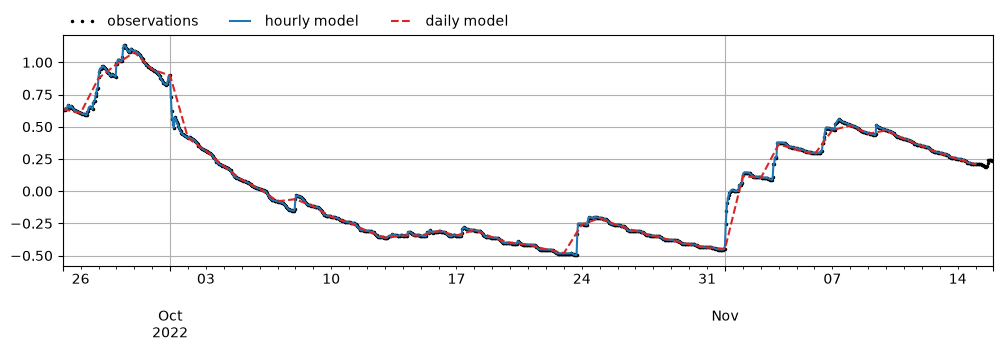
Comparing the estimated parameters with the true values we defined before, we
can see that the recharge estimates are very close to the actual values. For
the well the gain (well_A) is estimated well by both models. The parameters
a and b however, are only estimated well by the hourly model. This makes
sense because the daily model does not have sufficient observations in the
early periods after the start and end of pumping to estimate these parameters.
dfparams = c.get_parameters()
dfparams["True values"] = (A_rch, a_rch, f_rch, A_well, a_well, b_well, 0.0)
dfparams.round(4)
| d | h | True values | |
|---|---|---|---|
| recharge_A | 5004.1423 | 4993.4995 | 5000.0000 |
| recharge_a | 10.0051 | 9.9901 | 10.0000 |
| recharge_f | -1.0993 | -1.1028 | -1.1000 |
| well_A | -0.0002 | -0.0002 | -0.0002 |
| well_a | 0.0243 | 0.2053 | 0.2000 |
| well_b | 0.6866 | 0.0932 | 0.1000 |
| constant_d | 0.0004 | 0.0013 | 0.0000 |
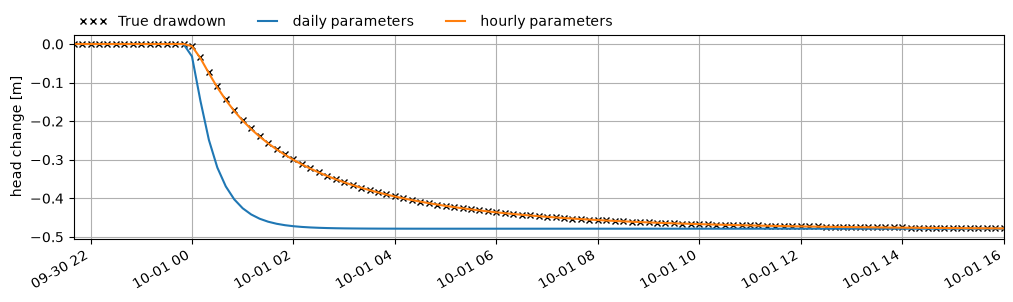
The consequence of the daily model not being able to estimate the parameters
a and b is clearly visible if we use the estimated parameters by both
models to reconstruct drawdown curves on a 10-minute interval. The parameters
estimated by the hourly model clearly follow the true drawdown, whereas
parameters of the daily model get the steady-state drawdown right, but not the
drawdown in the early stages after the well starts pumping.
dd_d_10M = generate_synthetic_heads(
qw, ps.Hantush(), ml_d.get_parameters("well"), dt=1 / (24 * 6.0)
)
dd_h_10M = generate_synthetic_heads(
qw, ps.Hantush(), ml_h.get_parameters("well"), dt=1 / (24 * 6.0)
)
fig, ax = plt.subplots(1, 1, figsize=(12, 3))
h_well.plot(
ax=ax, x_compat=True, label="True drawdown", marker="x", color="k", ls="none", ms=5
)
dd_d_10M.plot(ax=ax, label="daily parameters", x_compat=True)
dd_h_10M.plot(ax=ax, label="hourly parameters", x_compat=True)
ax.legend(loc=(0, 1), frameon=False, ncol=3, numpoints=3)
ax.set_ylabel("head change [m]")
ax.set_xlim(qw.index[130], qw.index[240])
ax.grid(True)