Bayesian uncertainty analysis#
R.A. Collenteur, Hydroconsult, May, 2026
In this notebook it is shown how the MCMC-algorithm can be used to estimate the model parameters and quantify the (parameter) uncertainties for a Pastas model using a Bayesian approach. For this purpose the EmceeSolver is introduced, based on the emcee Python package.
Besides Pastas the following Python Packages have to be installed to run this notebook:
import corner
import emcee
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import pastas as ps
ps.set_log_level("ERROR")
ps.show_versions()
Pastas : 2.0.0
Python : 3.14.6
Numpy : 2.4.6
Pandas : 3.0.5
Scipy : 1.18.0
Matplotlib : 3.11.1
Numba : 0.66.0
1. Create a Pastas Model#
The first step is to create a Pastas Model, including the RechargeModel to simulate the effect of precipitation and evaporation on the heads. Here, we first estimate the model parameters using the standard least-squares approach. Although not necessary, this is a convenient approach to obtain initial parameter values to generate the priors of the parameters later on.
head = pd.read_csv(
"data/B32C0639001.csv", parse_dates=["date"], index_col="date"
).squeeze()
evap = pd.read_csv("data/evap_260.csv", index_col=0, parse_dates=[0]).squeeze()
rain = pd.read_csv("data/rain_260.csv", index_col=0, parse_dates=[0]).squeeze()
ml = ps.Model(head)
ps.ArNoiseModel(ml)
# Select a recharge model
rch = ps.rch.Linear()
rm = ps.RechargeModel(ml, rain, evap, recharge=rch, rfunc=ps.Exponential(), name="rch")
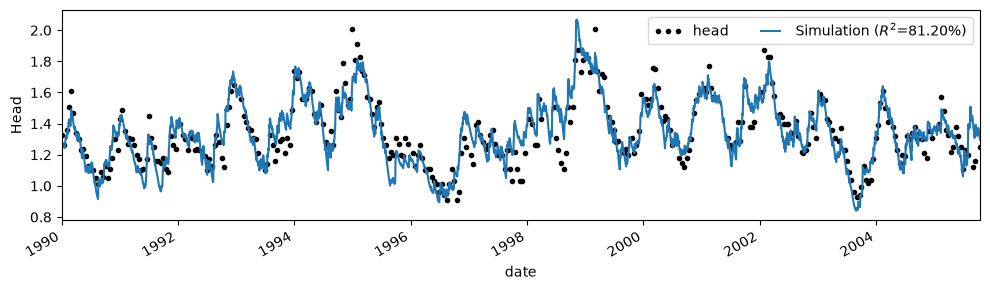
ml.solve(tmin="1990", report="full")
ax = ml.plot(figsize=(10, 3))
Fit report head Fit Statistics
==================================================
nfev 27 EVP 81.20
nobs 351 R2 0.81
noise True RMSE 0.09
tmin 1990-01-01 00:00:00 AICc -1957.61
tmax 2005-10-14 00:00:00 BIC -1938.48
freq D Obj nan
freq_obs None ___
warmup 3650 days 00:00:00 Interp. No
Parameters (5 optimized)
==================================================
optimal initial vary stderr
rch_A 0.271017 0.198424 True ±4.23%
rch_a 88.306116 10.000000 True ±0.21%
rch_f -0.543803 -1.000000 True ±11.67%
constant_d 0.942220 1.359779 True ±4.19%
noise_alpha 51.786859 15.000000 True ±16.46%
Parameter correlations |rho| > 0.5
==================================================
rch_A constant_d -0.75
rch_f constant_d -0.87
2. Use the EmceeSolver#
We will now use the EmceeSolve solver to estimate the model parameters and their uncertainties. This solver wraps the Emcee package, which implements different versions of MCMC. A good understanding of Emcee helps when using this solver, so it is recommended to read their documentation as well.
To set up the solver, a number of decisions need to be made:
Determine the priors of the parameters
Choose a (log) likelihood function
Choose the number of steps and thinning
2a. Create the solver instance#
The first step is to create an instance of the EmceeSolve solver class. At this stage all the settings need to be provided on how the Ensemble Sampler is created (https://emcee.readthedocs.io/en/stable/user/sampler/). Important settings are the nwalkers, the moves, the objfunction. More advanced options are to parallelize the MCMC algorithm (parallel=True), and to set a backend to store the results. The solver should be added before using ml.solve to estimate the parameters. Here’s an example:
ml_mc = ml.copy("ml_mc")
ml_mc.del_noisemodel()
# Choose the objective function
ln_prob = ps.likelihood.GaussianLikelihoodAr1()
# Create the EmceeSolver with some settings
s = ps.solver.Emcee(
model=ml_mc,
nwalkers=20,
moves=emcee.moves.DEMove(),
objfunction=ln_prob,
progress_bar=True,
parallel=False,
)
In the above code we created an EmceeSolve instance with 20 walkers, which take steps according to the DEMove move algorithm (see Emcee docs), and a Gaussian likelihood function that assumes AR1 correlated errors. Different objective functions are available, see the Pastas documentation on the different options.
ml_mc.parameters
| initial | pmin | pmax | vary | name | sigma | dist | optimal | |
|---|---|---|---|---|---|---|---|---|
| rch_A | 0.271017 | 1.000000e-05 | 19.842364 | True | rch | NaN | NaN | 0.271017 |
| rch_a | 88.306116 | 1.000000e-02 | 10000.000000 | True | rch | NaN | NaN | 88.306116 |
| rch_f | -0.543803 | -2.000000e+00 | 0.000000 | True | rch | NaN | NaN | -0.543803 |
| constant_d | 0.942220 | NaN | NaN | True | constant | NaN | NaN | 0.942220 |
| solver_var | 0.050000 | 1.000000e-10 | 1.000000 | True | solver | 1.0 | norm | NaN |
| solver_phi | 0.500000 | 1.000000e-10 | 0.999990 | True | solver | 1.0 | norm | NaN |
Depending on the likelihood function, a number of additional parameters need to be inferred. These parameters are added to the Pastas Model instance. The solver also add new columns to the parameter DataFrame with information necessary for the MCMC method. Using the set_parameter method of the model, these parameters can be changed. It is important to ensure that the ml.parameters is filled with information before using ml.solve.
In this example where we use the GaussianLikelihoodAr1 function the var and phi are estimated; the unknown standard deviation of the errors and the autoregressive parameter.
ml_mc.set_parameter("solver_var", initial=0.0028, vary=False, dist="norm", sigma=0.01)
ml_mc.parameters
| initial | pmin | pmax | vary | name | sigma | dist | optimal | |
|---|---|---|---|---|---|---|---|---|
| rch_A | 0.271017 | 1.000000e-05 | 19.842364 | True | rch | NaN | NaN | 0.271017 |
| rch_a | 88.306116 | 1.000000e-02 | 10000.000000 | True | rch | NaN | NaN | 88.306116 |
| rch_f | -0.543803 | -2.000000e+00 | 0.000000 | True | rch | NaN | NaN | -0.543803 |
| constant_d | 0.942220 | NaN | NaN | True | constant | NaN | NaN | 0.942220 |
| solver_var | 0.002800 | 1.000000e-10 | 1.000000 | False | solver | 0.01 | norm | NaN |
| solver_phi | 0.500000 | 1.000000e-10 | 0.999990 | True | solver | 1.00 | norm | NaN |
2b. Choose and set the priors#
The next step is to choose and set the priors of the parameters. This is done by using the ml.set_parameter method and the dist argument (from distribution). Any distribution from the scipy.stats can be chosen (https://docs.scipy.org/doc/scipy/tutorial/stats/continuous.html), for example uniform, norm, or lognorm. Here, for the sake of the example, we set all prior distributions to a normal distribution. We also set the sigma to the standard error of the parameters. The values for loc and scale in the scipy distributions are taken from the optimal or initial en sigma columns, respectively.
# Set the initial parameters to a normal distribution
ml_mc.set_parameter("constant_d", pmin=0.0, pmax=2.0)
for name in ml_mc.parameters.index:
ml_mc.set_parameter(name, dist="norm")
for name in ml.parameters.index:
if name in ml_mc.parameters.index:
ml_mc.set_parameter(name, sigma=ml.parameters.at[name, "stderr"])
ml_mc.parameters
| initial | pmin | pmax | vary | name | sigma | dist | optimal | |
|---|---|---|---|---|---|---|---|---|
| rch_A | 0.271017 | 1.000000e-05 | 19.842364 | True | rch | 0.011457 | norm | 0.271017 |
| rch_a | 88.306116 | 1.000000e-02 | 10000.000000 | True | rch | 0.182076 | norm | 88.306116 |
| rch_f | -0.543803 | -2.000000e+00 | 0.000000 | True | rch | 0.063471 | norm | -0.543803 |
| constant_d | 0.942220 | 0.000000e+00 | 2.000000 | True | constant | 0.039479 | norm | 0.942220 |
| solver_var | 0.002800 | 1.000000e-10 | 1.000000 | False | solver | 0.010000 | norm | NaN |
| solver_phi | 0.500000 | 1.000000e-10 | 0.999990 | True | solver | 1.000000 | norm | NaN |
Pastas will use the initial value of the parameter for the loc argument of the distribution (e.g., the mean of a normal distribution), and the stderr as the scale argument (e.g., the standard deviation of a normal distribution). Only for the parameters with a uniform distribution, the pmin and pmax values are used to determine a uniform prior. By default, all parameters are assigned a uniform prior.
2c. Run the solver and solve the model#
After setting the parameters and creating a EmceeSolve solver instance we are now ready to run the MCMC analysis. We can do this by running ml.solve. We can pass the same parameters that we normally provide to this method (e.g., tmin or fit_constant). Here we use the initial parameters from our least-square solve. Note that we do not fit a noise model, because we already take autocorrelated errors into account through the likelihood function.
All the arguments that are not used by ml.solve, for example steps and tune, are passed on to the run_mcmc method from the sampler (see Emcee docs). The most important is the steps argument, that determines how many steps each of the walkers takes.
# Use the solver to run MCMC
ml_mc.solve(
initial=False,
tmin="1990",
steps=100,
tune=True,
)
Fit report ml_mc Fit Statistics
=======================================================
nwalkers 20 EVP 81.43
nsteps 100 R2 0.81
nobs 351 RMSE 0.09
tmin 1990-01-01 00:00:00 AICc -1682.39
tmax 2005-10-14 00:00:00 BIC -1663.26
freq D Obj nan
freq_obs None ___
warmup 3650 days 00:00:00 Interp. No
Parameters (5 optimized)
=======================================================
optimal initial vary sigma dist
rch_A 0.266966 0.271017 True 0.011457 norm
rch_a 88.318426 88.306116 True 0.182076 norm
rch_f -0.554648 -0.543803 True 0.063471 norm
constant_d 0.949765 0.942220 True 0.039479 norm
solver_var 0.002800 0.002800 False 0.010000 norm
solver_phi 0.732453 0.500000 True 1.000000 norm
0%| | 0/100 [00:00<?, ?it/s]
1%| | 1/100 [00:00<00:12, 7.96it/s]
3%|▎ | 3/100 [00:00<00:10, 9.66it/s]
5%|▌ | 5/100 [00:00<00:09, 10.00it/s]
7%|▋ | 7/100 [00:00<00:09, 10.27it/s]
9%|▉ | 9/100 [00:00<00:08, 10.36it/s]
11%|█ | 11/100 [00:01<00:08, 10.37it/s]
13%|█▎ | 13/100 [00:01<00:08, 10.43it/s]
15%|█▌ | 15/100 [00:01<00:08, 10.45it/s]
17%|█▋ | 17/100 [00:01<00:07, 10.42it/s]
19%|█▉ | 19/100 [00:01<00:07, 10.43it/s]
21%|██ | 21/100 [00:02<00:07, 10.39it/s]
23%|██▎ | 23/100 [00:02<00:07, 10.35it/s]
25%|██▌ | 25/100 [00:02<00:07, 10.32it/s]
27%|██▋ | 27/100 [00:02<00:07, 10.35it/s]
29%|██▉ | 29/100 [00:02<00:06, 10.41it/s]
31%|███ | 31/100 [00:03<00:06, 10.43it/s]
33%|███▎ | 33/100 [00:03<00:06, 10.42it/s]
35%|███▌ | 35/100 [00:03<00:06, 10.38it/s]
37%|███▋ | 37/100 [00:03<00:06, 10.36it/s]
39%|███▉ | 39/100 [00:03<00:05, 10.37it/s]
41%|████ | 41/100 [00:03<00:05, 10.38it/s]
43%|████▎ | 43/100 [00:04<00:05, 10.38it/s]
45%|████▌ | 45/100 [00:04<00:05, 10.35it/s]
47%|████▋ | 47/100 [00:04<00:05, 10.39it/s]
49%|████▉ | 49/100 [00:04<00:04, 10.47it/s]
51%|█████ | 51/100 [00:04<00:04, 10.54it/s]
53%|█████▎ | 53/100 [00:05<00:04, 10.54it/s]
55%|█████▌ | 55/100 [00:05<00:04, 10.55it/s]
57%|█████▋ | 57/100 [00:05<00:04, 10.56it/s]
59%|█████▉ | 59/100 [00:05<00:03, 10.60it/s]
61%|██████ | 61/100 [00:05<00:03, 10.60it/s]
63%|██████▎ | 63/100 [00:06<00:03, 10.57it/s]
65%|██████▌ | 65/100 [00:06<00:03, 10.56it/s]
67%|██████▋ | 67/100 [00:06<00:03, 10.51it/s]
69%|██████▉ | 69/100 [00:06<00:02, 10.54it/s]
71%|███████ | 71/100 [00:06<00:02, 10.57it/s]
73%|███████▎ | 73/100 [00:07<00:02, 10.59it/s]
75%|███████▌ | 75/100 [00:07<00:02, 10.47it/s]
77%|███████▋ | 77/100 [00:07<00:02, 10.53it/s]
79%|███████▉ | 79/100 [00:07<00:01, 10.57it/s]
81%|████████ | 81/100 [00:07<00:01, 10.59it/s]
83%|████████▎ | 83/100 [00:07<00:01, 10.59it/s]
85%|████████▌ | 85/100 [00:08<00:01, 10.58it/s]
87%|████████▋ | 87/100 [00:08<00:01, 10.54it/s]
89%|████████▉ | 89/100 [00:08<00:01, 10.44it/s]
91%|█████████ | 91/100 [00:08<00:00, 10.51it/s]
93%|█████████▎| 93/100 [00:08<00:00, 10.55it/s]
95%|█████████▌| 95/100 [00:09<00:00, 10.56it/s]
97%|█████████▋| 97/100 [00:09<00:00, 10.58it/s]
99%|█████████▉| 99/100 [00:09<00:00, 10.62it/s]
100%|██████████| 100/100 [00:09<00:00, 10.46it/s]
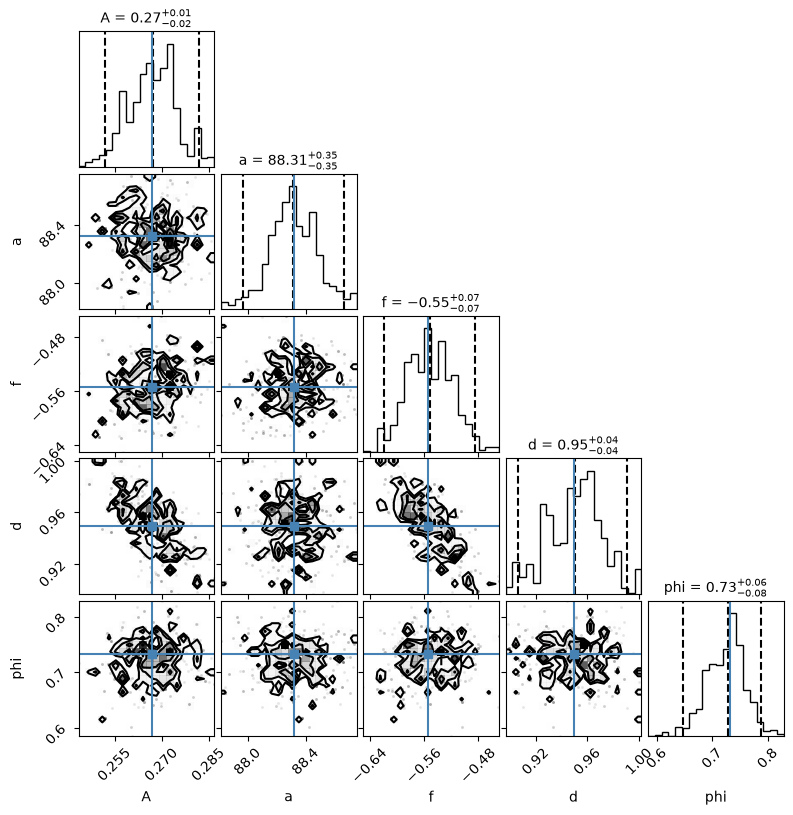
3. Posterior parameter distributions#
The results from the MCMC analysis are stored in the sampler object, accessible through ml.solver.sampler variable. The object ml.solver.sampler.flatchain contains a Pandas DataFrame with \(n\) the parameter samples, where \(n\) is calculated as follows:
\(n = \frac{\left(\text{steps}-\text{burn}\right)\cdot\text{nwalkers}}{\text{thin}} \)
Corner.py#
Corner is a simple but great python package that makes creating corner graphs easy. A couple of lines of code suffice to create a plot of the parameter distributions and the covariances between the parameters.
# Corner plot of the results
fig = plt.figure(figsize=(8, 8))
labels = list(ml_mc.parameters.index[ml_mc.parameters.vary])
labels = [label.split("_")[1] for label in labels]
best = list(ml_mc.parameters[ml_mc.parameters.vary].optimal)
axes = corner.corner(
ml_mc.solver.sampler.get_chain(flat=True, discard=50),
quantiles=[0.025, 0.5, 0.975],
labelpad=0.1,
show_titles=True,
title_kwargs=dict(fontsize=10),
label_kwargs=dict(fontsize=10),
max_n_ticks=3,
fig=fig,
labels=labels,
truths=best,
)
plt.show()
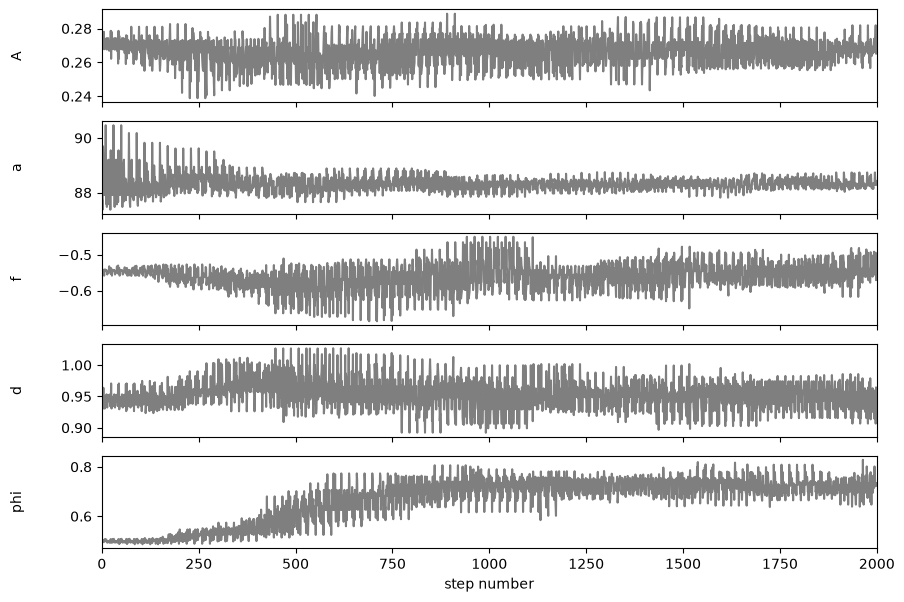
4. What happens to the walkers at each step?#
The walkers take steps in different directions for each step. It is expected that after a number of steps, the direction of the step becomes random, as a sign that an optimum has been found. This can be checked by looking at the autocorrelation, which should be insignificant after a number of steps. Below we just show how to obtain the different chains, the interpretation of which is outside the scope of this notebook.
fig, axes = plt.subplots(len(labels), figsize=(10, 7), sharex=True)
samples = ml_mc.solver.sampler.get_chain(flat=True)
for i in range(len(labels)):
ax = axes[i]
ax.plot(samples[:, i], "k", alpha=0.5)
ax.set_xlim(0, len(samples))
ax.set_ylabel(labels[i])
ax.yaxis.set_label_coords(-0.1, 0.5)
axes[-1].set_xlabel("step number")
Text(0.5, 0, 'step number')
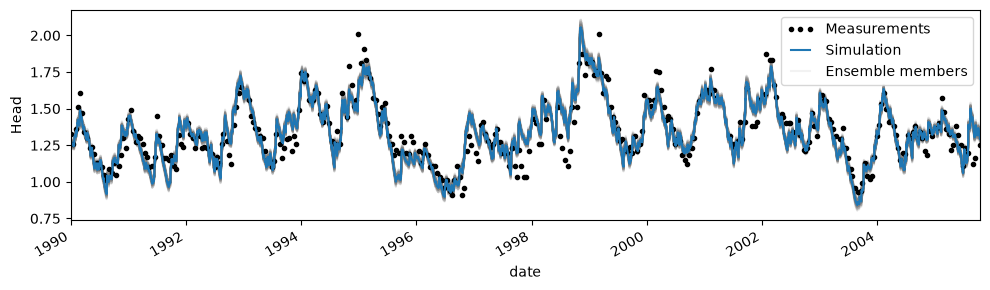
5. Plot some simulated time series to display uncertainty?#
We can now draw parameter sets from the chain and simulate the uncertainty in the head simulation.
# Plot results and uncertainty
ax = ml_mc.plot(figsize=(10, 3))
plt.title(None)
chain = ml_mc.solver.sampler.get_chain(flat=True, discard=50)
inds = np.random.randint(len(chain), size=100)
for ind in inds:
params = chain[ind]
p = ml.parameters.optimal.copy().to_numpy(copy=True)
p[ml.parameters.vary] = params[: ml.parameters.vary.sum()]
_ = ml.simulate(p, tmin="1990").plot(c="gray", alpha=0.1, zorder=-1)
plt.legend(["Measurements", "Simulation", "Ensemble members"], numpoints=3);